Problem 31 : LLMs - What’s under the hood?
Reuters reported artificial intelligence (AI) as a defining feature of 2023. AI is an umbrella term that encompasses a bunch of capabilities that demonstrate machine intelligence within which Generative AI which is a specific kind of Deep Learning (DL) technology has been making the rounds. This has been so profound that Bloomberg Intelligence (BI) reported a CAGR of 42% for the Generative AI market (combining infrastructure, services and products) to as high as 1.32 Trillion USD by 2032! Whether its Google’s Bard, xAI’s Grock or OpenAI’s ChatGPT, all of these Large Language Models are Generative Pre-Trained Transformers (GPTs) that have over tens of billions (175 billion for ChatGPT) of parameters and are trained on a large corpus of text. Below is the embedded Google Trends Result for LLMs.
Naturally, I became interested in understanding the true ramifications of such models and being more of a fundamentalist made me want to see what is happening under the hood. I wanted to see if I could explain in a style that retains some of the essential math while helping build an understanding of what makes these models seemingly powerful.
Generating Embeddings - Words to Vectors
It is easy to realize that we cannot simply feed words into a neural network, we need numbers. A naive approach to achieve this would be an array as large as the whole dictionary of words in the corpus of text that would have binary values for mapping a word to a unique array. This approach is called “Bag of Words” and could quickly become cumbersome for a large database where each word would require such an array. There is a much better way of dealing with this..
Before we begin, a quick review of feed-forward neural network is necessary. A typical feed-forward neural network is composed of an input layer that for now say takes in a vector valued input. Subsequent information passage happens through the hidden layers that reside in between the input and output layer. On the output side, an output vector is computed. Nodes in the NN are connected through real-valued weights that can be cleanly represented through weight matrices (W) with dimensionality n x m for a connectivity between simultaneous layers with n and m nodes each.
Now, let us say that we want to capture all these words somehow while also capturing “information” of the context under which these words typically appear in our corpus. Alternatively, we want to project the words onto a “meaning space” which can be used to represent words with fewer dimensions. To do this, we need some notion of “closeness” in the “meaning space” and this is precisely where a simple feed-forward NN trained for a task that forces it to learn this notion of “closeness”. One such task is predicting word that appears amidst the words around it (prediction of the word based on context) and another is predicting words around a specific word (prediction of context based on the word). In either case, we are predicting “words” that appear in a certain context. Read more about Skip-gram and Continuous Bag of Words.
Training of such a NN that predicts neighbouring words once done using the naive “Bag of Words” approach, provides an entirely new way to represent words. How? – By simply looking at the output of the last hidden layer. Why? – The output layer in this case uses softmax to return a probability vector representing the probability of the “neighboring” word. The numbers that get fed to the output layer would be representative of “closeness”.
Minor note: In NLP, not only whole words but also bits and pieces of words (tokens) are converted to real-valued vectors (embeddings) are then used as input

We have a way to change words/tokens to numbers but now what?
Can we use feed-forward NN? Evidently, a simple feed-forward neural network cannot synthesize text because the task of predicting words requires the context of the previous word. Recurrent Neural Networks (RNNs)? Probably, but that would only consider the previous word with information passage happening through an internal state variable passed on from the previous network in the series. The answer seems to be something known as “self-attention” or an “attention head”. Self-attention layers serve as a building block of transformers.
Attention is all you need (2017)
The quest to build a building block led to some apparently intuitive ways to deal with the input embeddings. Simple matrix multiplication with the embeddings i.e., say, a list of embeddings typically denoted as \(x_1, x_2, x_3, \dots\). A concatenated set of these embeddings \(X\) is then used to compute three new internal vectors: Queries (Q), Keys (K) and Values (V). I am not sure about the exact role of each vector. Mathematically, each vector Q, K and V is formed out of corresponding learned matrices \(W_Q\), \(W_K\) and \(W_V\) by multiplying each of them with \(X\). The high-level idea seems to be that Q and K are linear transformations of the embeddings such that together they tell how “appropriate” a token is at a given position. Therefore, the normalized product \(\frac{QK^T}{\sqrt{d_k}}\) is fed to softmax in the last step of a self-attention block and each row of this is used to perform a weighted sum of the Values (V) corresponding to the \(i^{th}\) token. Mathematically, these are summarized below,
\[Q = X*W_Q \\ K = X*W_K \\ V = X*W_V\]and for the final normalized product, \(Z = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)*V\)
where \(Z\) is the final output score that captures the “context” (Why? – My intuition says that, the \(QK^T\) term captures “connection between the words” and \(V\) seems to be capturing the strength of these “connectivities”).

Transformers
With the self-attention mechanism in mind, the transformer architecture can now be understood.
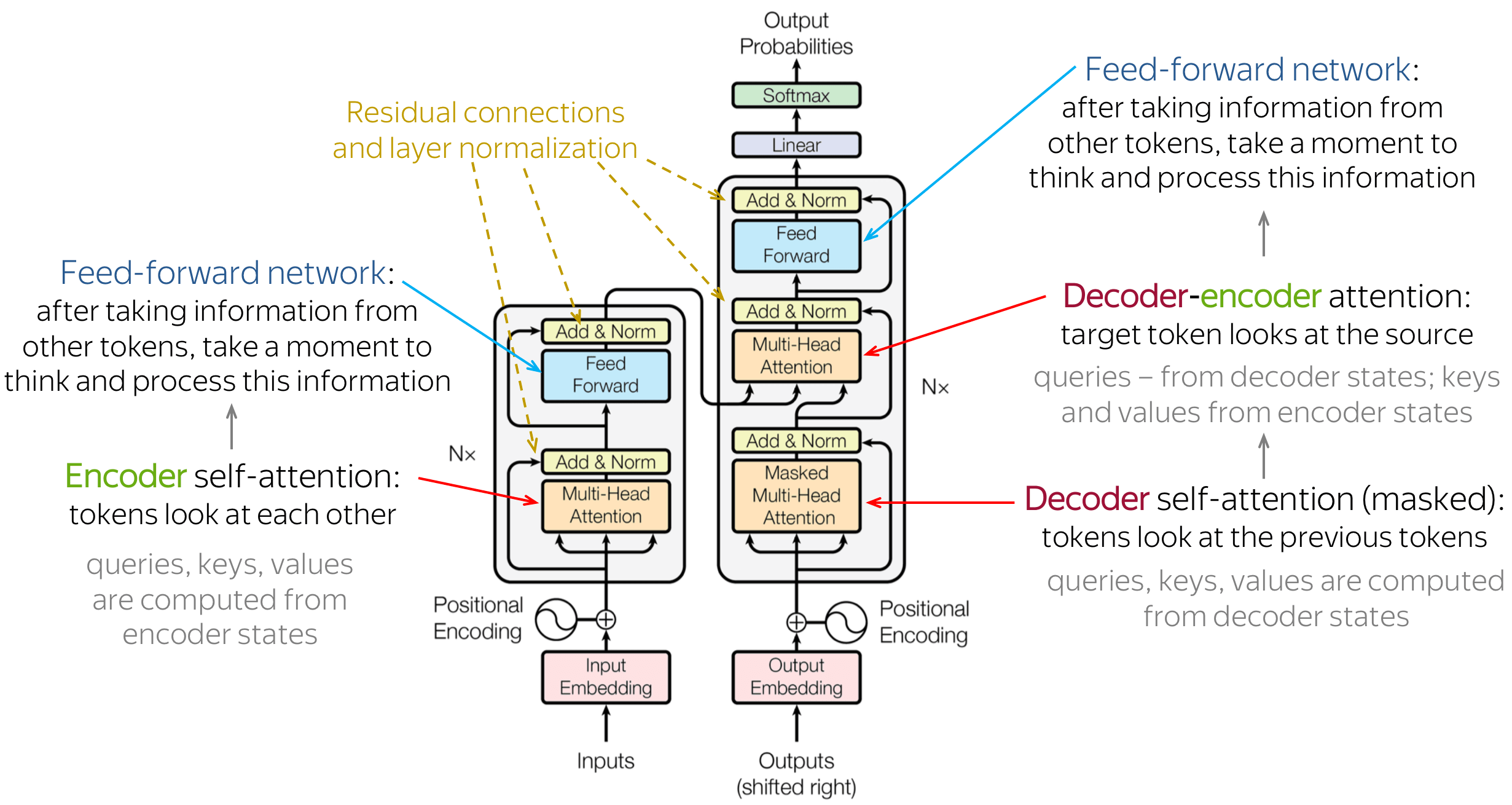
Essentially, the outputs \(Z\) from the self-attention layer carry contextual information about the embeddings (i.e. the input \(X\)) that is then passed to a feed-forward NN to output a new set to finally generate an “internal” representation of \(X\). The self-attention layer coupled with the feed-forward NN is together called an encoder block (Note that it is also common to stack multiple encoders one after another). This output which is a new set of vectors say, \(X_{encoded}\) is then passed to another block known as the Decoder.
The decoder is pretty similar to the encoder with a self-attention layer just like the encoder that creates the contextual representation of the words outputted so far (basically does all of the self-attention math again leading to \(Q_{dec}\), \(K_{dec}\), \(V_{dec}\)). But we also need something to capture the original context of the input \(X\) this has to come from the encoder block (encoded input words are needed to capture the context under which the output is being generated). This is done in an “encoder-decoder” within the decoder block changing the output of the last encoder in the encoder block into two vectors \(K_{enc}\) and \(V_{enc}\) which are then fed with \(Q_{dec}\) from the aforementioned self-attention layer to create the final output \(Z_{dec}\) that is then passed to a feed-forward NN (just like the encoder block).
The final output at the top of a single or stacked set of decoder blocks is then fed to a linear layer that does a linear mapping from \(Z_{dec}\) to a massive vector that represents all the words. These values in the vector are then converted to probabilities using a softmax layer and subsequently used to pred the next “most” probable word.
Enter ChatGPT
So how does all this enter into ChatGPT? Simply put, ChatGPT uses transformers at a massive scale (175 billion parameters!). I think Stephen Wolfram’s article puts it in the best way…
“First, it takes the sequence of tokens that corresponds to the text so far and finds an embedding (i.e. an array of numbers) that represents these. Then it operates on this embedding—in a “standard neural net way”, with values “rippling through” successive layers in a network—to produce a new embedding (i.e. a new array of numbers). It then takes the last part of this array and generates from it an array of about 50,000 values that turn into probabilities for different possible next tokens. (And, yes, it so happens that there are about the same number of tokens used as there are common words in English, though only about 3000 of the tokens are whole words, and the rest are fragments.)”.
All of this is made possible using a massive corpus on training data. GPT is somehow able to “learn” the rules without any explicit inclusion of such rules! Sure, we can make some sense of it based on the architecture but I wonder if we could even reveal these “learned rules” from billions of parameters?